一、简介
本次学习主要根据《CUDA C编程权威指南》一书来学习,当然我也会在其基础上进行修改。感兴趣的话可以直接翻看原书。书的英文名为《Professional CUDA® C Programming》。
主要目的是熟悉GPU与CPU通信、GPU并行思想、简单的环境配置等。
二、配置环境
1、概述
我这里配置的环境是win10下的vscode+SSH+Linux+RTX3090。
2、具体操作
①win10下,安装vscode。
②vscode中安装SSH。
③Linux端安装NVIDIA相关驱动、GCC编译包、nvcc编译包。
④使用vscode的SSH连接至Linux端,并新建.cu类型的脚本,进而编译运行。
注:本文所使用的脚本类型均为.cu后缀。
三、第一个在GPU运行的HelloWorld程序
1、熟悉GPU架构
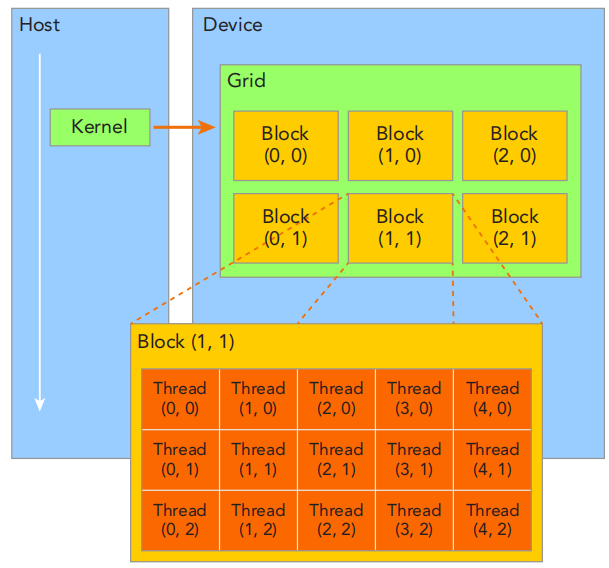
2、编写程序
①首先新建文件hello.cu,Linux下可以使用touch hello.cu。
②这个程序的main函数运行在CPU端,hello()函数则运行在GPU端。
③其中GPU是以grid、block、thread几个层级进行组织的。故«<grid,block»>也代表这一层级。
如下所示,表示grid开了(1,1,1)的block(也就是一个block),并且在每个block是(6,1,1)的thread。也就是说这个现在共有6个线程并行执行hello函数,当打印到第6个(0,1,2,3,4,5)时,输出线程的打印结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include <stdio.h>
#include <cuda.h>
#include <iostream>
using namespace std;
__global__ void hello() {
if(threadIdx.x == 5)
printf("Hello World from GPU thread %d\n",threadIdx.x);
}
int main() {
cout<<"Hello World from CPU"<<endl;
dim3 grid(1, 1, 1);
dim3 block(6, 1, 1);
hello<<<grid, block>>>();
cudaDeviceSynchronize();
cudaDeviceReset();
return 0;
}
注:GPU端似乎只能使用C语言进行编程,而CPU端则可以正常使用C++进行编程。
3、编译执行
编译使用nvcc指令,其中sm_86这里的数字86要根据自己的显卡来决定,具体可以在官网上查询。
1
nvcc -arch sm_86 hello.cu -o hello
4、输出结果
执行编译后的文件,输出结果为:
1
2
Hello World from CPU
Hello World from GPU thread 5
四、进阶
1、进一步熟悉grid和block
以下代码来自《CUDA C编程权威指南》一书。此代码则展示了当前checkIndex运行在GPU的哪个坐标,以及整个申请的grid、block大小是多少。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void checkIndex(void) {
printf("threadIdx:(%d, %d, %d) blockIdx:(%d, %d, %d) blockDim:(%d, %d, %d) "
"gridDim:(%d, %d, %d)\n", threadIdx.x, threadIdx.y, threadIdx.z,
blockIdx.x, blockIdx.y, blockIdx.z, blockDim.x, blockDim.y, blockDim.z,
gridDim.x,gridDim.y,gridDim.z);
}
int main(int argc, char **argv) {
// define total data element
int nElem = 6;
// define grid and block structure
dim3 block (3);
dim3 grid ((nElem+block.x-1)/block.x);
// check grid and block dimension from host side
printf("grid.x %d grid.y %d grid.z %d\n",grid.x, grid.y, grid.z);
printf("block.x %d block.y %d block.z %d\n",block.x, block.y, block.z);
// check grid and block dimension from device side
checkIndex <<<grid, block>>> ();
// reset device before you leave
cudaDeviceReset();
return(0);
}
其输出结果为:
1
2
3
4
5
6
7
8
grid.x 2 grid.y 1 grid.z 1
block.x 3 block.y 1 block.z 1
threadIdx:(0, 0, 0) blockIdx:(1, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
threadIdx:(1, 0, 0) blockIdx:(1, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
threadIdx:(2, 0, 0) blockIdx:(1, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
threadIdx:(0, 0, 0) blockIdx:(0, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
threadIdx:(1, 0, 0) blockIdx:(0, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
threadIdx:(2, 0, 0) blockIdx:(0, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
2、在GPU设备端与CPU主机之间进行数据的运算和传输
①GPU上运行计算程序一般分为如下几个步骤:
1
2
3
4
5
6
7
8
9
10
/***
1.DEV端设备初始化。
2.Host端变量声明、内存申请、初始化赋值。
3.DEV端变量声明、内存申请。
4.将Host端代码copy至DEV端。
5.调用核函数对存储在DEV内存中的数据进行操作。
6.将数据从DEV内存传送回到Host内存。
7.释放DEV内存
8.释放Host内存
***/
②首先我们看一段只在本地CPU进行数据运算的例子。重点关注sumArraysOnHost,这里使用的是for循环进行相加运算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
#include<stdlib.h>
#include<string>
#include<time.h>
#include<iostream>
using namespace std;
void sumArraysOnHost(float * A, float *B, float *C, const int N)
{
for(int idx = 0; idx<N; ++idx)
{
C[idx] = A[idx] + B[idx];
}
}
void initialData(float *ip, int size)
{
time_t t;
srand((unsigned) time(&t));
for(int i = 0; i < size; ++i)
{
ip[i] = (float)(rand() & 0xFF)/10.0f;
}
}
int main(int agrc, char **argv)
{
int nElem = 1024;
size_t nBytes = nElem * sizeof(float);
cout<<"nBytes = "<<nBytes<<endl;
float *h_A, *h_B, *h_C;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
h_C = (float *)malloc(nBytes);
initialData(h_A, nElem);
initialData(h_B, nElem);
sumArraysOnHost(h_A, h_B, h_C, nElem);
for(int i = 0; i < 10; ++i)
{
cout<<h_A[i]<<" + "<<h_B[i]<<" = "<<h_C[i]<<endl;
}
free(h_A);
free(h_B);
free(h_C);
return 0;
}
输出为:
1
2
3
4
5
6
7
8
9
10
11
nBytes = 4096
13.7 + 13.7 = 27.4
12.2 + 12.2 = 24.4
23.3 + 23.3 = 46.6
10.8 + 10.8 = 21.6
10.9 + 10.9 = 21.8
12.9 + 12.9 = 25.8
4.2 + 4.2 = 8.4
6.2 + 6.2 = 12.4
13.2 + 13.2 = 26.4
12.7 + 12.7 = 25.4
③进而,我们可以将sum这个函数变为GPU上可以运行的核函数,并且使用thread的id来作为循环变量来进行求和运算。最后使用checkResult函数来验证GPU运算和CPU运算结果是否一致。如下程序所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
#include <cuda_runtime.h>
#include <stdio.h>
#include <iostream>
using namespace std;
void checkResult(float *hostRef, float *gpuRef, const int N) {
double epsilon = 1.0E-8;
bool match = 1;
for (int i=0; i<N; i++) {
if (abs(hostRef[i] - gpuRef[i]) > epsilon) {
match = 0;
printf("Arrays do not match!\n");
printf("host %5.2f gpu %5.2f at current %d\n",hostRef[i],gpuRef[i],i);
break;
}
}
if (match)
printf("Arrays match.\n\n");
}
void initialData(float *ip,int size) {
// generate different seed for random number
time_t t;
srand((unsigned) time(&t));
for (int i=0; i<size; i++) {
ip[i] = (float)( rand() & 0xFF )/10.0f;
}
}
void sumArraysOnHost(float *A, float *B, float *C, const int N) {
for (int idx=0; idx<N; idx++)
C[idx] = A[idx] + B[idx];
}
__global__ void sumArraysOnGPU(float *A, float *B, float *C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main(int argc, char **argv) {
cout<<"Device is starting"<<endl;
// set up device
int dev = 0;
cudaSetDevice(dev);
cout<<"GPU device is #"<<dev<<endl;
// set up data size of vectors
int nElem = 32;
printf("Vector size %d\n", nElem);
// malloc host memory
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
initialData(h_A, nElem);
initialData(h_B, nElem);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// malloc device global memory
float *d_A, *d_B, *d_C;
cudaMalloc((float**)&d_A, nBytes);
cudaMalloc((float**)&d_B, nBytes);
cudaMalloc((float**)&d_C, nBytes);
// transfer data from host to device
cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice);
// invoke kernel at host side
dim3 block (nElem);
dim3 grid (nElem/block.x);
sumArraysOnGPU<<< grid, block >>>(d_A, d_B, d_C);
printf("Execution configuration <<<%d, %d>>>\n",grid.x,block.x);
// copy kernel result back to host side
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);
// add vector at host side for result checks
sumArraysOnHost(h_A, h_B, hostRef, nElem);
// check device results
checkResult(hostRef, gpuRef, nElem);
// free device global memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
return(0);
}
输出结果为:
1
2
3
4
5
Device is starting
GPU device is #0
Vector size 32
Execution configuration <<<1, 32>>>
Arrays match.
3、内存申请、释放、拷贝
可以看到上述程序中已经加入很多之前没有用过的函数,例如cudaMemcpy、cudaFree、cudaMalloc等。
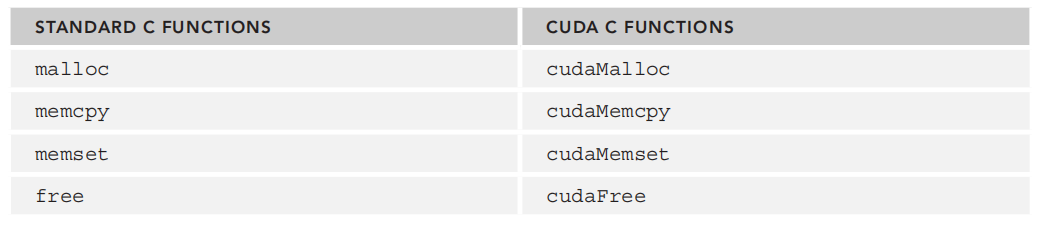
其实这些函数和C语言中在CPU上申请内存、释放内存、内存拷贝的功能相似,只不过是在cuda上进行内存的申请和释放罢了。
cudaMalloc和cudaMemcpy的函数原型分别为:
1
cudaError_t cudaMalloc ( void** devPtr, size_t size )
1
2
3
4
5
6
cudaError_t cudaMemcpy ( void* dst, const void* src, size_t count, cudaMemcpyKind kind )
//kind包括
//➤ cudaMemcpyHostToHost
//➤ cudaMemcpyHostToDevice
//➤ cudaMemcpyDeviceToHost
//➤ cudaMemcpyDeviceToDevice